



在计算语言学的领域里,生成语法(generative grammar)是重要的研究的方向之一。生成语法的主要目标是让程序可以自动判定一句话的语法正确性(grammatical),在给出判断的同时,生成语法也可以对被判定的句子进行句法分析(syntactic parsing)和附带的基本的语义分析(semantic parsing)。在深度学习主宰自然语言处理界的今天,计算语言学和生成语法所代表的符号主义(symbolism)已经不再具有可以独立挑战深度学习的可能性,但符号主义所拥有的优势恰恰是深度学习所缺失的。这篇文章不讨论如何结合两者,但会用一个叫中心词驱动短语结构语法(HPSG: Head-Driven Phrase Structure Grammar)的生成语法来简单介绍符号主义视角下的语言理解方案。
[1] Syntax theory: a formal introduction
[2] DELPH-IN
生成语法的分支有不少,最早也是最出名的是由乔姆斯基(chomsky)提出的转换生成语法(transformational grammar)。而后续的发展使得生成语法出现了分支,一种以减轻规则数量而把语言的惯例(conventions)和限制(constraints)下放到词典(lexicon)的思路逐渐诞生,HPSG也是这种词汇化(lexicalized)思路下发展出来的语法。虽然对于计算语言学的研究者们来说,这些分支的区别很大,但对计算机科学背景的研究者来讲,这些区别并不重要,所有的生成语法都是可以用程序语言描述的,而HPSG则是这其中有相对完善的软件支持的语法[2]。
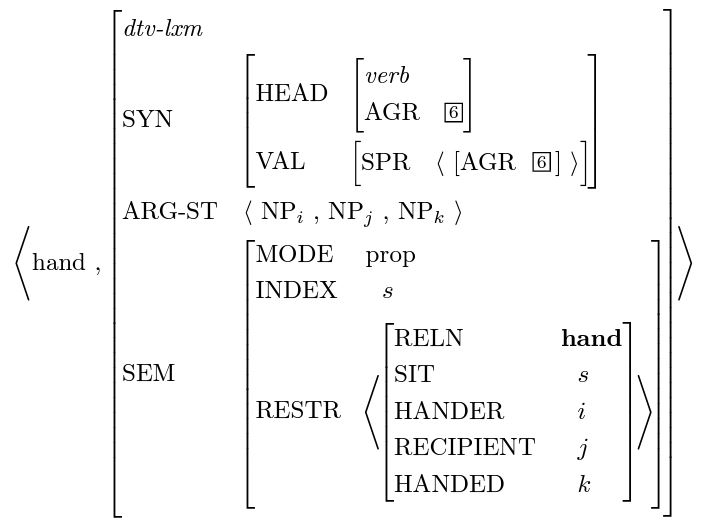
Lexicon包含了HPSG中绝大部分的关于语言惯例和语法限制的信息,以上图的动词hand为例,这样的一个结构被称为lexical entry,每一个lexical entry都包含了3样重要的信息:syntax(SYN),argument-structure (ARG-ST)和semantics (SEM)。
其中SYN用来记录这个词的基本属性,例如词性,单复数,时态等等,而specifier(SPR)和complements(COMPS)则记录了对这个词产生影响的前后的词(specifier为前,complements为后)。在这个例子中,动词hand由于受到英语subject verb agreement的影响,其单复数形式会和自己的主语一致(第三人称主语用hands),所以hand的agreement和自己的specifier的agreement保持一致。在HPSG,描述这样的限制是靠两个相同的索引完成的([6]),这样的索引可以放置在任何结构任何位置。
而ARG-ST则是用来描述这个词在句子里完整而且必要的语境,其作用和语言模型类似。例如动词give:[somebody] give [something] [to somebody],give的ARG-ST可以要求第二个complement必须是一个以to开头的名词短语。一般来说,ARG-ST可以被拆分成SYN里的specifier和complements,但在long term dependency的情况下,specifier或者complements可以被省略掉,假设被省略掉的部分在之前已经出现过。而这个现象在很多语言都存在,举一个中文的例子:[我]信得过[这个人],信得过的specifier是[我],complements是[这个人]。
但在long term dependency的现象下,complements可以被移到前面:[这个人],[我]信得过。在HPSG里,如果specifier或者complements有缺失,缺失的短语将被登记到一个叫gap的值上,等处理到拥有更大视野的时候,HPSG才会把这个gap值补上。所以specifier,complements和gap可以完整地描述ARG-ST,即一个词必要的语境,这个语境在任何可以接受这个词的句子都必须存在。
而最后的一部分信息则是对自然语言处理最重要的SEM,以上面的lexical entry为例子,hand这个动作涉及到三个实体:hander,recipient和handed。而ARG-ST则决定了这三个实体在语境中的顺序,比如[I] hand [the baby] [a toy], 这里的[I]是hander, [the baby] 是 recipient,而[a toy]则是handed。在HPSG的设计中,如果ARG-ST的值可以在一个句子中被推导出来,那么实体之间的关系自然也就可以被准确地描述出来,用计算语言学家的话来说:syntax are scaffolds for semantics。
为了让同一个词适应不同的语态,时态和语境,HPSG有不同的lexical rule来对词素(lexeme)或者词(word)进行转变。
1. Derivational Rules: 词素到词素的转变,在inflection rule之前可以转变多次
2. Inflectional Rule: 从词素到词转换,一个词只能有一次inflection rule转变
3. Post Inflectional Rule:一般用于调整词的语境来应对一些语言现象,例如inversion(did变成didn't)

一个简单的例子是被动语态(passive voice),为了让动词hand适应被动语态的句子,上图的derivational rule可以把一个词的ARG-ST里的实体变换顺序,然后再给主语加上一个介词by。这样一来:[I] hand [the baby] [a toy] 就可以变成 [the baby] was handed [a toy] [by me]。下图是被动语态规则的输入(左)与输出(右),注意只有ARG-ST(也就是语境)变了,SYN和SEM都不变,这个规则可以适用于所有的transitive verb,也就是及物动词。
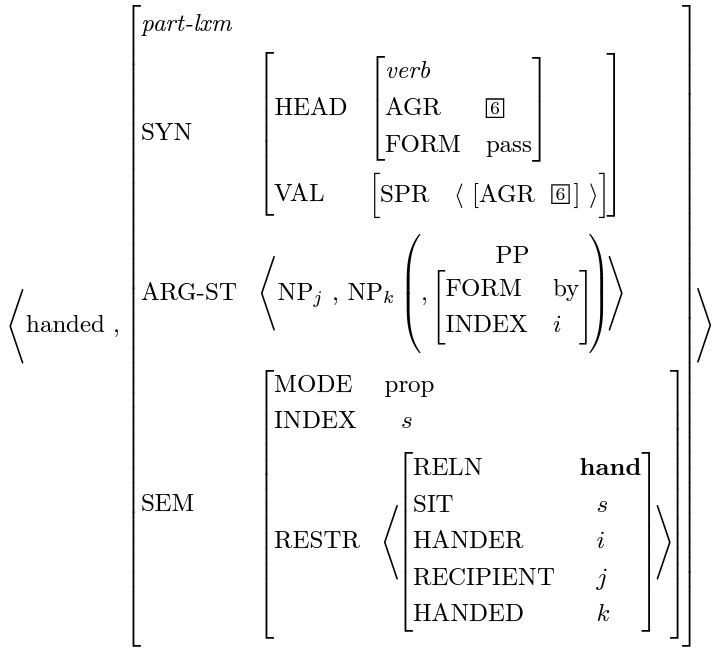
与计算机科学里的面向对象编程类似,HPSG里的lexical entry可以继承自一个更笼统的父类,然后再通过lexical rule进行转变,这样做的主要目的是缩小lexicon,次要目的是让HPSG对词的归纳可以反映出语言的本质。
因为大部分的信息都下放到了lexicon,HPSG本身的grammar rules非常的少,HPSG的教科书([1])里只用了一页半列就列举完了能覆盖绝大多数句子的基本grammar rules:
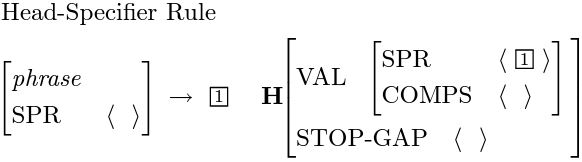



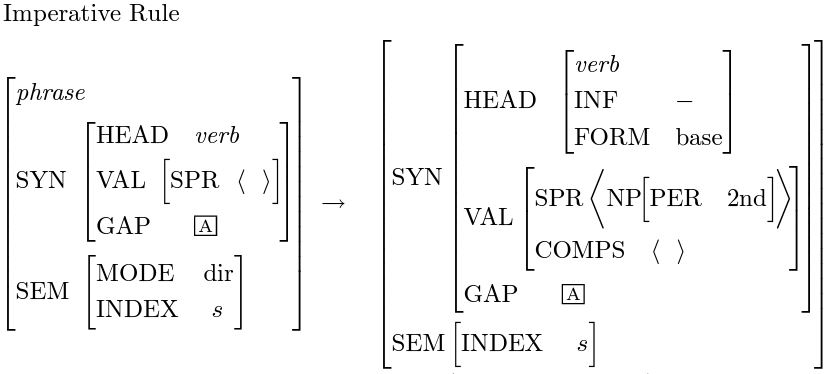
其中有"H"标记的就是HPSG中心词(head daughter)。当HPSG对着一个句子生成句法树时,树里的每一个节点都会有N个子节点(终端节点除外),而最重要的节点就是中心词所在的节点。中心词的主要任务是向上传递局部信息,例如SYN值和SEM值。中心词之所以有传递信息的能力,主要是由lexicon的设计决定的,许多的助动词例如have,be,can, will之类的都被设计成传递信息的中转站。在HPSG里,中心词一般按以下的优先顺序选出:(V > VP > P > PP > N > NP), 其他的词(C, CP, D, DP, A, AP)则有特殊的固定搭配。所以对于一个句子,大概的句法分析过程可以归纳如下:
1. 确定每个词的lexical entry
2. 从下到上用中心词和grammar rules形成新的节点,直到根节点被建立
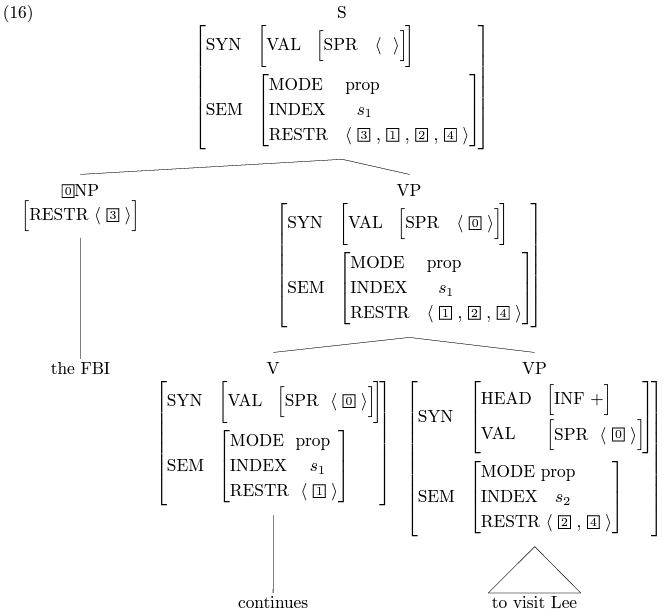
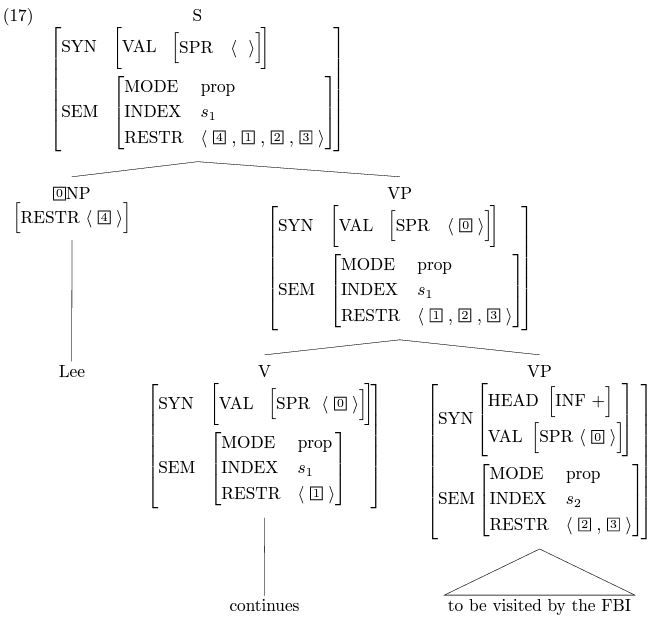
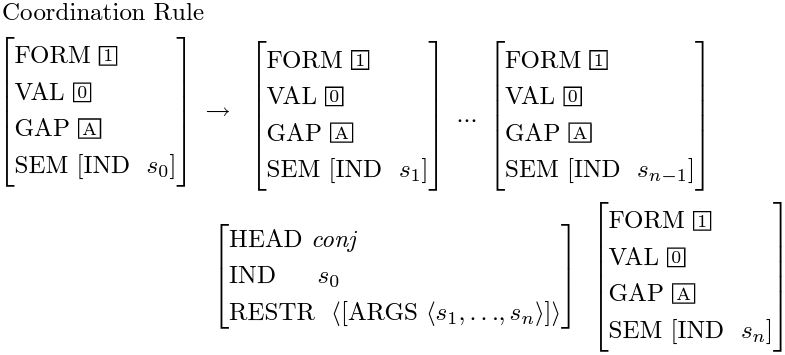
上面的两幅图简单地描述了句法分析的过程,其中的动词continues是中心词中的中心词,所以整个句子的索引(INDEX)和continues的索引是一样的(都为s1)。The FBI continues to visit lee (上图) 在被动语态下是 Lee continues to be visited by the FBI,顺着同样的过程,根节点都得出了一模一样的SEM值,如下图:
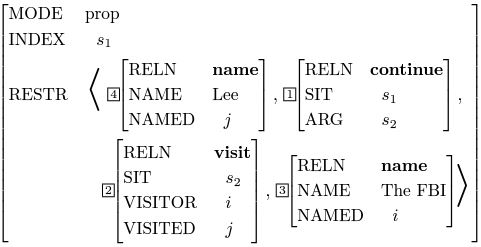
SEM值里的RESTR(restriction)是包括了所有终端节点的实体关系组(predication),而且RESTR是一个集合的概念,所以实体关系组的顺序并不重要,也就是说只要能找到每个词里ARG-ST所对应的实体,实体关系组就能在终端节点被确定,而无论句子是用什么语态或者时态表达出来的,根节点都能得出一样的语义。
以下摘自HPSG的教科书[2]的8.9:
An important insight, going back at least to Saussure, is that all languages involve arbitrary (that is, unpredictable) information. Most clearly, the association between the forms (sounds) and meanings of words is purely conventional, in the vast majority of cases. A grammar of a language must list these associations somewhere. The original conception of the lexicon in modern linguistics was simply as the repository of such arbitrary information.
从计算语言学家的角度来看,任何语言都包含了大量看起来随机而且没有规律的知识,而语言形式和语义之间的联系很大程度上是惯例决定的(也就是自古以来的用法)。一个能把从语言形式(form)转换到语义(semantics)的语言理解系统必须要记录大量的琐碎知识,这个观察是推动的计算语法词汇化的最重要的推动力。在2020的今天,这个目标其实已经被深度学习下的大型语言模型实现了,词向量和神经网络本身就有大量的参数来记忆这些琐碎的知识,而端对端学习框架易于优化的优点又能让深度学习模型可以很可靠地从大量的数据中获取这些知识。相反是HPSG所代表的生成语法这种靠人工编辑lexicon的做法显得非常的低效过时,HPSG对语法正确性的要求更是让其实用性受到了致命的打击,这也是我认为符号主义(symbolism)的系统不具有可以独立挑战深度学习的根本原因。
但是从另外一个观点看,HPSG这种对形式和语义的清晰分层,是深度学习难以做到的。深度学习端对端的思路从形式作为输入开始,一直到特定应用的决策输出(例如问答系统的多选题),中间并没有允许语义层存在的空间,更不用说语义层上的语用层(pragmatics)。这样的学习是非常低效的(low data efficiency),这也助长了近年来神经网络越做越大,数据越用越多的思路。把语义层和语用层植入现有的语言理解系统,一定是解开自然语言理解的必经之路。