



計算言語学の分野において、生成文法(generative grammar)は重要な研究の方向性の一つです。生成文法の主な目標は、プログラムが自動的に文の文法的正しさ(grammatical)を判定することができるようにすることです。判定を行う際に、生成文法は判定された文に対して構文解析(syntactic parsing)および基本的な意味解析(semantic parsing)を行うこともできます。深層学習が自然言語処理界を支配する今日において、計算言語学と生成文法が代表する象徴主義(symbolism)は、もはや深層学習に独立して挑戦する可能性を持たないが、象徴主義が持つ利点は、深層学習が欠けているものでもあります。この記事では、両者を結びつける方法については議論せず、中心語駆動型句構造文法(HPSG: Head-Driven Phrase Structure Grammar)と呼ばれる生成文法を用いて、象徴主義の視点からの言語理解の手法を簡単に紹介します。
[1] 構文理論: 形式的入門
[2] DELPH-IN
生成文法の枝分かれは多く、最も古く最も有名なのはチョムスキー(chomsky)によって提唱された変換生成文法(transformational grammar)です。その後の発展により、生成文法には枝分かれが生じ、一つは規則の数を減らしながら言語の慣習(conventions)と制約(constraints)を辞書(lexicon)に下放する考え方が次第に生まれ、HPSGもこのような語彙化(lexicalized)思考の下で発展した文法です。計算言語学の研究者にとっては、これらの枝分かれの違いは大きいですが、コンピュータサイエンスのバックグラウンドを持つ研究者にとっては、これらの違いは重要ではなく、すべての生成文法はプログラミング言語で記述可能であり、HPSGはその中で相対的に整ったソフトウェアサポートのある文法です[2]。
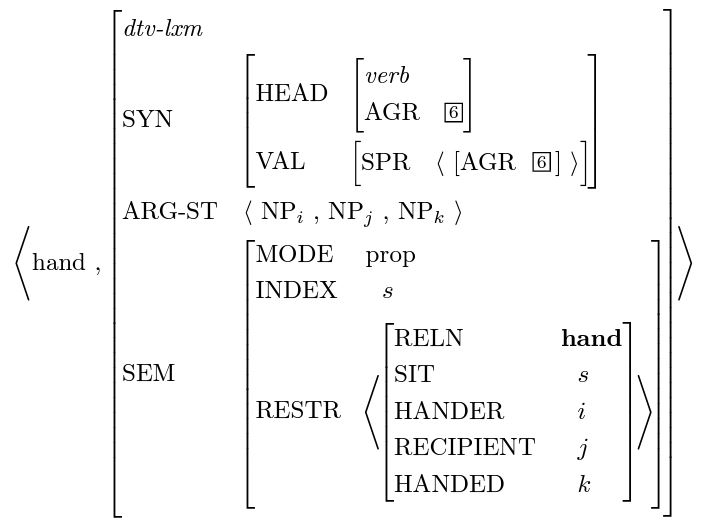
LexiconはHPSGの中で言語慣習や文法制約に関する情報の大部分を含んでいます。上の図の動詞handを例にとると、このような構造はレキシカルエントリーと呼ばれます。各レキシカルエントリーは、3つの重要な情報を含んでいます:構文(SYN)、引数構造(ARG-ST)、および意味(SEM)。
SYNはこの単語の基本的な属性、例えば品詞、単数・複数、時制などを記録するために使用され、specifier(SPR)とcomplements(COMPS)はこの単語に影響を与える前後の単語を記録します(前はspecifier、後はcomplements)。この例では、動詞handは英語の主語動詞一致(subject verb agreement)の影響を受け、その単数・複数形は自分の主語と一致します(三人称主語はhands)。したがって、handのagreementは自分のspecifierのagreementと一致します。HPSGでは、こうした制約を記述するために二つの同一のインデックスが用いられます([6])。このインデックスはどの構造のどの位置にも置くことができます。
ARG-STは、この語が文の中で完全かつ必要な文脈を説明するために用いられ、その作用は言語モデルに似ています。例えば動詞give:[somebody] give [something] [to somebody]の場合、giveのARG-STは第二のcomplementが必ずtoで始まる名詞句であることを要求します。一般的に、ARG-STはSYNのspecifierとcomplementsに分解できますが、long term dependencyの状況下では、specifierやcomplementsは省略可能で、その省略された部分が以前に現れたと仮定されます。この現象は多くの言語に存在し、中国語の例を挙げると:[我]信得过[这个人]、信得过のspecifierは[我]、complementsは[这个人]です。
しかし、長期依存の現象において、complementsは前に移動することができます:[这个人]、[我]は信頼できます。HPSGでは、specifierまたはcomplementsが欠如している場合、欠如したフレーズはgapという値に登録されます。そして、より広い視野を持つことになった時に、HPSGはこのgapの値を補完します。したがって、specifier、complements、およびgapはARG-STを完全に記述することができ、すなわち単語に必要な文脈、これはその単語を受け入れることができる任意の文に存在しなければなりません。
最終部分の情報は、自然言語処理において最も重要なSEMです。上記のlexical entryを例として、handという動作は3つのエンティティ、つまりhander、recipient、handedに関わっています。そしてARG-STは、文脈におけるこれら3つのエンティティの順序を決定します。たとえば、[I] hand [the baby] [a toy]のように、ここで[I]はhander、[the baby]はrecipient、[a toy]はhandedとなります。HPSGの設計において、ARG-STの値が文中で導出される場合、エンティティ間の関係も正確に記述されることが可能となります。計算言語学者の言葉を借りれば、syntax are scaffolds for semanticsです。
異なる態、時制、文脈に適応するために、HPSGは語素(lexeme)または単語(word)を変換する異なるレキシカルルールを持っています。
1. 派生ルール: 形態素から形態素への変化で、屈折ルールの前に何度も変化できる
2. 屈折ルール: 形態素から単語に変換され、単語は屈折ルールの変化を一度だけ持つことができる
3. ポスト屈折ルール:一般に、いくつかの言語現象、例えば逆転(didがdidn'tに変化する)に対応するために単語の文脈を調整するために使用される

一つの簡単な例は受動態(passive voice)であり、動詞handを受動態の文に適応させるために、上の図の派生ルール(derivational rule)が単語のARG-STの中のエンティティの順序を変更し、主語に前置詞byを加えます。こうすることで:[I] hand [the baby] [a toy] は [the baby] was handed [a toy] [by me] に変化します。下の図は受動態ルールの入力(左)と出力(右)であり、注意すべきはARG-ST(すなわち文脈)だけが変わり、SYNとSEMはそのままであることです。このルールはすべての他動詞(transitive verb)に適用可能です。
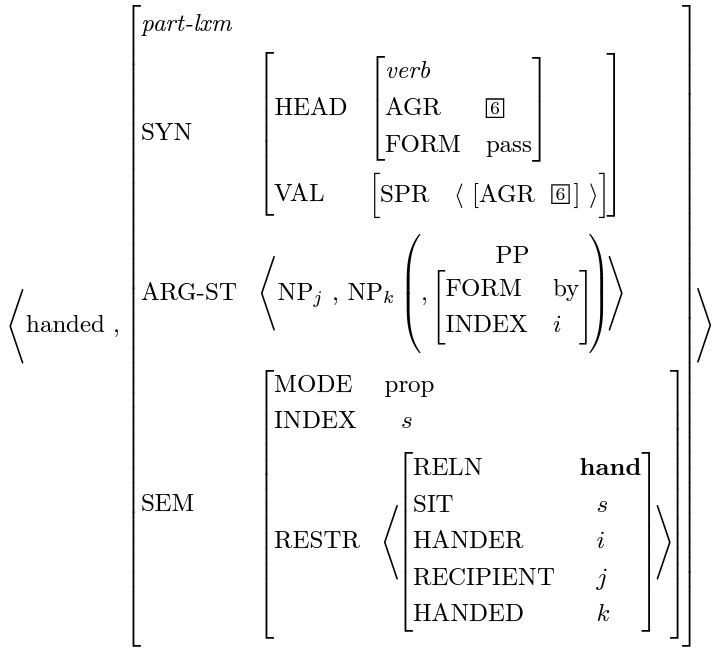
計算機科学のオブジェクト指向プログラミングに似て、HPSGのlexical entryはより一般的な親クラスから継承することができ、次にlexical ruleを通じて変化させることができます。このようにする主な目的はlexiconを縮小することであり、二次的な目的はHPSGが語の帰納を通じて言語の本質を反映できるようにすることです。
情報はほとんどがレキシコンに移されているため、HPSG自体の文法規則は非常に少なく、HPSGの教科書([1])では、ほとんどの文をカバーできる基本的な文法規則を1ページ半で列挙しています:
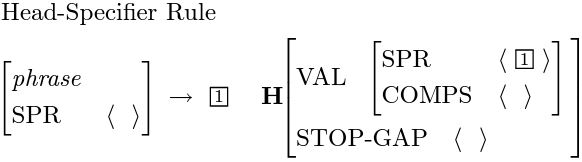



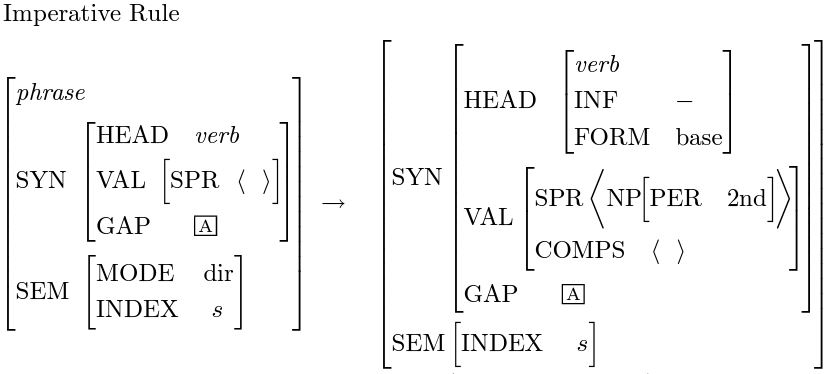
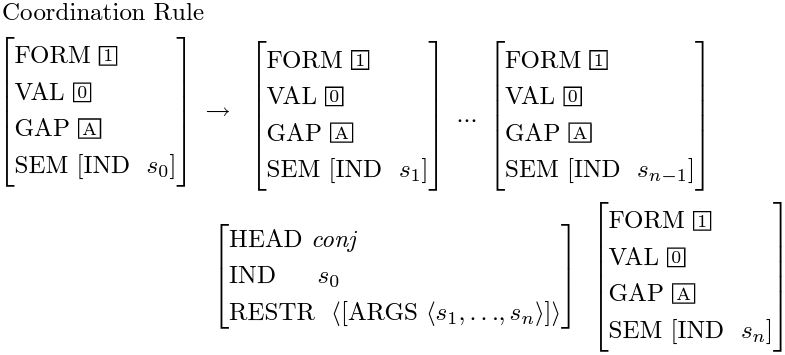
"H"マークが付いているのがHPSG中心語(head daughter)です。HPSGが文に対して文法木を生成する際、木内の各ノードはN個の子ノードを持ち(終端ノードを除く)、最も重要なノードは中心語の所在ノードです。中心語の主な役割は局所情報、例えばSYN値やSEM値を上位に伝達することです。中心語が情報を伝達する能力を持つ理由は、主にレキシコンの設計によるもので、多くの助動詞(have、be、can、willなど)が情報を伝達する中継地点として設計されています。HPSGでは、中心語は通常次の優先順位で選出されます:(V > VP > P > PP > N > NP)、その他の語(C、CP、D、DP、A、AP)は特別な固定の組み合わせを持っています。したがって、文に対する大まかな文法分析過程は次のように要約できます:
1. 各単語のレキシカルエントリーを特定する
2. 中心語と文法ルールを用いて、根ノードが確立されるまで新しいノードを下から上へ形成する
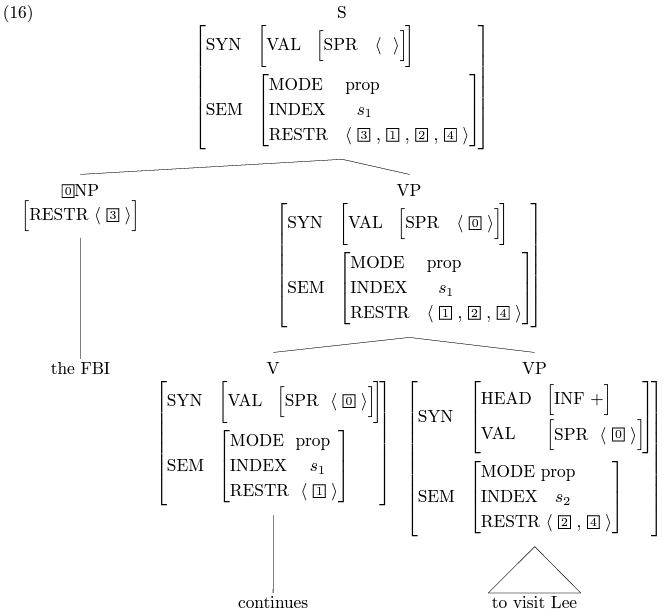
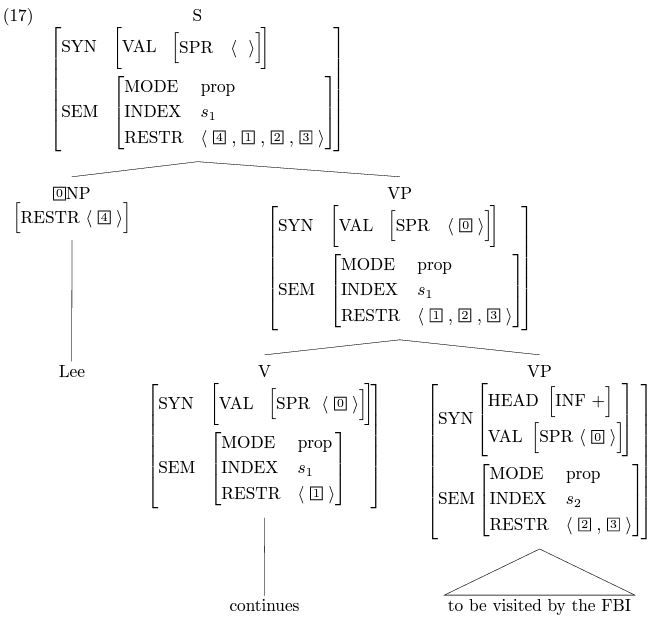
上の2つの図は、構文解析の過程を簡単に説明しています。その中の動詞continuesは中心語の中心語であるため、文全体のインデックス(INDEX)とcontinuesのインデックスは同じです(どちらもs1です)。The FBI continues to visit lee (上図) は受動態では、Lee continues to be visited by the FBIとなります。同じプロセスに従って、根のノードはすべて同じSEM値を導き出し、下の図のようになります:
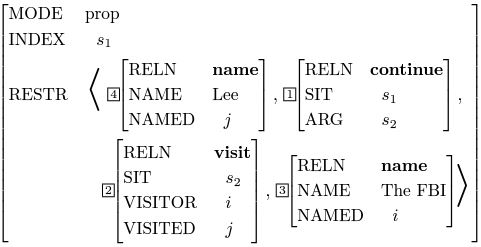
SEM値のRESTR(制約)は、すべての端末ノードのエンティティ関係群(述語)を含んでいます。また、RESTRは集合の概念であるため、エンティティ関係群の順序は重要ではありません。つまり、各単語のARG-STに対応するエンティティが見つかれば、エンティティ関係群は端末ノードで特定できます。文がどのような態や時制で表現されても、根ノードは同じ意味を導き出せます。
以下はHPSGの教科書[2]の8.9からの引用です:
重要な洞察は、少なくともソシュールまで遡るが、すべての言語は恣意的(つまり、予測不可能な)情報を含むということです。最も明確なのは、単語の形(音)と意味との間の関連が、ほとんどすべての場合において純粋に慣習的であることです。言語の文法は、これらの関連をどこかにリストしなければなりません。現代言語学におけるレキシコンの元々の概念は、単にそのような恣意的情報の保管庫としてのものでした。
計算言語学者の視点から見ると、どの言語も大量のランダムで規則性のない知識を包含しており、言語形式と意味の間の関係は大部分が慣習に依存しています(つまり、古くからの用法です)。言語形式(form)から意味(semantics)への変換を行う言語理解システムは、大量の細かい知識を記録する必要があります。この観察は、計算文法の語彙化を推進する最も重要な要因です。2020年の現在、この目標は実際にディープラーニングによる大規模言語モデルによって実現されています。単語ベクトルと神経ネットワーク自体は、多くのパラメータを持ち、これらの細かい知識を記憶できます。また、エンドツーエンドの学習フレームワークは最適化しやすい利点があり、ディープラーニングモデルは大量のデータからこれらの知識を信頼性高く取得できます。それに対して、HPSGが代表する生成文法のような人工的に編集されたレキシコンに依存するアプローチは非常に非効率で時代遅れのものであり、HPSGの文法正確性への要求はその実用性を致命的に打撃しています。これが、私が符号主義(symbolism)システムがディープラーニングに独立して挑戦できる根本的な理由を持たないと考える理由でもあります。
しかし、別の視点から見ると、HPSGの形式と意味の明確な階層は、ディープラーニングには難しいことです。ディープラーニングのエンド・ツー・エンドの考え方は、形式を入力として始まり、特定のアプリケーションの意思決定出力(例えば、質問応答システムの選択問題)まで続きますが、その間に意味層が存在する余地はありません。また、意味層の上にある語用層(pragmatics)については言うまでもありません。このような学習は非常に非効率的(low data efficiency)であり、近年、神経ネットワークがますます大きくなり、データがますます多くなる考え方を助長しています。意味層と語用層を既存の言語理解システムに組み込むことは、自然言語理解を解決する必経の道であるに違いありません。