



これは、強化学習に馴染みのない私のような機械学習の人々のための、近接ポリシー最適化(2020年のベスト強化学習アルゴリズム)に関する基本的な紹介です。
Hung-yi Leeの講義(中国語)
近接ポリシー勾配(論文)
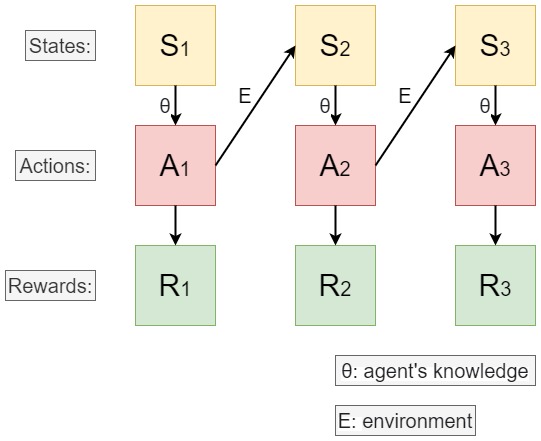
強化学習の問題定義は、環境とエージェントの相互作用に基づいています。上に示すように、各状態はエージェントが環境に対して行った観察を表します。各状態が与えられると、エージェントは将来の報酬を最大化するために知識に基づいて行動を取ります。相互作用は、状態と行動のシーケンスを生成します。このようなシーケンスを $\tau$ と示す場合、
$$ \tau = \{ s_1, a_1, s_2, a_2, s_3, a_3 ... \} \tag{サンプルデータ} $$
$\tau$の期待報酬を書き下ろすことができるのは、$\tau$がランダム変数であるためです。
$$ \bar{R_{\theta}} = E_{\tau \sim p_\theta(\tau)} \big[ R(\tau) \big] = \sum_{\tau} R(\tau) p_{\theta}(\tau) ,\,\,\, R(\tau) = \sum_{i}^{T} r_t $$
深層強化学習の場合、 $\theta$ は期待報酬を最大化するために調整したいニューラルネットワークの重みです。
この期待報酬を最適化するために、私たちはその導関数を取ることができます,
\begin{align} \nabla \bar{R_{\theta}} &= \sum_{\tau} R(\tau) \nabla p_{\theta}(\tau) \\ &= \sum_{\tau} R(\tau) p_{\theta}(\tau) \nabla \log p_{\theta}(\tau) \tag{$ \nabla \log f(x) = \frac{\log f(x)}{f(x)}$} \\ &= E_{\tau \sim p_\theta(\tau)} \big[ R(\tau) \nabla \log p_\theta(\tau) \big] \\ &\approx \frac{1}{N} \sum_{n=1}^{N} R(\tau^n) \nabla \log p_\theta(\tau^n) \\ &= \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} R(\tau^n) \nabla \log p_\theta(a_t^n | s_t^n) \tag{$ \nabla \log p_\theta(\tau^n) = \sum_{t=1}^{T_n} \nabla \log p_\theta(a_t^n | s_t^n) $}\\ \end{align}
そして、$\theta$を勾配降下法で調整します、
$$ \theta \leftarrow \theta + \eta \nabla \bar{R_{\theta}} $$
これは、シーケンスの報酬によって重み付けされた各時間ステップでのアクションの対数尤度を最大化することに相当します。しかし、私たちは間違ったアクションの尤度も最大化しますが、ソフトマックスの下では、理想的なシナリオでは、より高い報酬を持つアクションが常により高い発生確率を持ちます。もう一つの問題は、実際にはすべてのアクションをサンプリングすることができないということです。部分的なサンプリングからのバイアスを排除するために、低報酬アクションを罰するために、正の定数項 $b$ を引くことができます。
$$ \nabla \bar{R_{\theta}} \approx \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} (R(\tau^n) - b) \nabla \log p_\theta(a_t^n | s_t^n) $$
代替の解決策は、報酬項をクリティックネットワークに置き換えることです。
$$ \nabla \bar{R_{\theta}} \approx \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} A^{\theta}(s_t, a_t) \nabla \log p_\theta(a_t^n | s_t^n) $$
上記の最適化アプローチはオンポリシー最適化と呼ばれますが、実際には、勾配降下法によって必要なパスの数が通常サンプルデータの数を超えるため、オフポリシー最適化が使用されました。 このような設定では、別のエージェントによって以前にサンプリングされたデータに基づいて$\theta$を最適化したいと考えます。この手順は次のとおりです:
1. エージェントを使ってサンプルデータ $D$ を取得し、重み $\theta_2$ を使用します。
2. データ $D$ を使用して重み $\theta$ のエージェントを最適化します(複数回)
3. 重みを同期: $\theta_2 \leftarrow \theta$
$\theta$と$\theta_2$は異なる2つの分布を生成するため、期待報酬を修正するために重要性サンプリングと呼ばれる技術を使用する必要があります。分布$p$の下での期待値は、別の分布$q$を使用して書き換えることができます。
$$ E_{x \sim p} [f(x)] = \int f(x) p(x) dx = \int f(x) \frac{p(x)}{q(x)} q(x) dx = E_{x \sim q} [f(x) \frac{p(x)}{q(x)}] $$
私たちのポリシー勾配を振り返りましょう、
$$ \nabla \bar{R_{\theta}} = E_{(a_t, s_t) \sim p_\theta(\tau)} [A^{\theta}(s_t, a_t) \nabla \log p_\theta(a_t | s_t)] $$
もし私たちが、$\theta$(学習者エージェント)のための期待報酬を$\theta_2$(環境内のエージェント)から重要性サンプリングを使って書き直すと、次のようになります,
\begin{align} \nabla \bar{R_{\theta}} &= E_{(a_t, s_t) \sim p_{\theta_2}(\tau)} [\frac{ p_{\theta_2}(a_t, s_t) }{ p_{\theta}(a_t, s_t) } A^{\theta_2}(s_t, a_t) \nabla \log p_\theta(a_t | s_t)] \\ &= E_{(a_t, s_t) \sim p_{\theta_2}(\tau)} [\frac{ p_{\theta_2}(a_t | s_t) }{ p_{\theta}(a_t | s_t) } A^{\theta_2}(s_t, a_t) \nabla \log p_\theta(a_t | s_t)] \tag{$p_{\theta}(s_t) = p_{\theta_2}(s_t)$}\\ \end{align}
上記のポリシー勾配の積分を取ると、重要性サンプリングの設定における新しい期待報酬が得られます,
\begin{align} \bar{R_{\theta}} = E_{(a_t, s_t) \sim p_{\theta_2}(\tau)} [\frac{ p_{\theta_2}(a_t | s_t) }{ p_{\theta}(a_t | s_t) } A^{\theta_2}(s_t, a_t) ] \tag{ $ \nabla \log f(x) = \frac{\log f(x)}{f(x)}$ } \end{align}
重要性サンプリングの追加が期待報酬に影響を与えないことを示しました、
$$ E_{x \sim p} [f(x)] = E_{x \sim q} [f(x) \frac{p(x)}{q(x)}] $$
しかし、これら二つの設定における報酬の分散は異なります、
$$ Var_{x \sim p} [f(x)] \neq Var_{x \sim q} [f(x) \frac{p(x)}{q(x)}] $$
バニラの設定では、
$$ Var_{x \sim p} [f(x)] = E_{x \sim p} [f(x)^2] - (E_{x \sim p} [f(x)])^2 \tag{分散の定義} $$
重要性サンプリングの設定では、
\begin{align} Var_{x \sim q} [f(x) \frac{p(x)}{q(x)}] &= E_{x \sim q} [(f(x) \frac{p(x)}{q(x)})^2] - (E_{x \sim q} [f(x) \frac{p(x)}{q(x)}])^2 \\ &= E_{x \sim p} [f(x)^2 \frac{p(x)}{q(x)}] - (E_{x \sim p} [f(x)])^2 \end{align}
$p(x)$ が $q(x)$ と非常に異なる場合、重要性サンプリング技術の効果は低下します。実際には、$p(x)$ を $q(x)$ に近づけたいと考えています。
$p(x)$と$q(x)$の差を制約するために、近接ポリシー勾配は重要性サンプリングの上に正則化項を追加します,
$$ \bar{R^{\theta}_{PPO}} = E_{(a_t, s_t) \sim p_{\theta_2}(\tau)} [\frac{ p_{\theta_2}(a_t | s_t) }{ p_{\theta}(a_t | s_t) } A^{\theta_2}(s_t, a_t) ] + \beta KL (\theta, \theta_2) $$
ここで、$KL (\theta, \theta_2)$ は $ p_{\theta} (a_t \vert s_t) $ と $ p_{\theta_2} (a_t \vert s_t) $ のKLダイバージェンスであり、$\beta$ はハイパーパラメータです。直感的には、以前に訓練されたエージェントに基づいて新しいエージェントを構築する際には、新しいエージェントが出発点からあまりにも異なりすぎないことを望みます。これにより、アルゴリズムはモデルに対してより細かいが漸進的な更新を行うことができます。代わりに、$\epsilon$ というハイパーパラメータを使用してこのアイデアを実装するためにクリッピングを行うこともできます。
$$ \bar{R^{\theta}_{PPO_2}} = E_{(a_t, s_t) \sim p_{\theta_2}(\tau)} [min( \frac{ p_{\theta_2}(a_t | s_t) }{ p_{\theta}(a_t | s_t) } A^{\theta_2}(s_t, a_t), \, clip(\frac{ p_{\theta_2}(a_t | s_t) }{ p_{\theta}(a_t | s_t) }, 1-\epsilon, 1+\epsilon) A^{\theta_2}(s_t, a_t), )] $$
もし $A^{\theta_2}(s_t, a_t) > 0$ (良い行動)であれば、$\frac{ p_{\theta_2}(a_t \vert s_t) }{ p_{\theta}(a_t \vert s_t) }$ の上限を $ 1 + \epsilon $ に設定します。もし $A^{\theta_2}(s_t, a_t) < 0$ (悪い行動)であれば、$\frac{ p_{\theta_2}(a_t \vert s_t) }{ p_{\theta}(a_t \vert s_t) }$ の下限を $ 1 - \epsilon $ に設定します。